
Eu trabalho em um projeto de software distribuído. Daqueles que, diz Leslie Lamport, é do tipo que "um computador que você não sabia que existia quebra e torna o seu computador inutilizável no processo". Esta é uma coletânea de observações que fiz ao longo dos anos, de problemas presentes, e de soluções interessantes. Eu mesmo sentia a necessidade de expressar tudo que penso, porém, de uma vez só. Assim deixo um relato de como podemos nos sincronizar para ficarmos todos ...
... na mesma cadência
Está tudo escrito pelas estrelas: em um projeto de software nós sempre elencamos o que precisa ser feito, fazemos uma estimativa da complexidade e do esforço, priorizamos o que é desejável de se fazer e mãos à obra. Conforme as coisas vão ficando prontas elas vão sendo entregues e gerando pequenos incrementos no produto final, o seu cliente pode visitar sua "obra" durante a construção e conferir se está tudo no direcionamento que ele quer, e o feedback constante mantém as engrenagens lubrificadas com a confiança um no outro.
E ainda assim as coisas não saem como planejado: equipes andam amarradas em uma dança macabra de dependências umas com as outras, o forte acoplamento entre elas impossibilita entrega contínua e gradual, complexidade de implementação implica em complicações para a manutenção, e o fluxo de demandas canalizadas à sede de faturamento causa uma enxurrada que leva embora qualquer pensamento de melhoria contínua.
Em um sistema distribuído a percepção do usuário final é de uma coisa só, indiferente a qualquer coisa que se tenha por debaixo do capô. Então, como possivelmente podemos melhorar a entrega do nosso conjunto?
Entrelaçamento quase-quântico
É moda entre alguns adeptos de práticas de trambicagem coaching falar que tudo é "quântico" hoje em dia. Não, de tudo o que eles falam muito provavelmente nada é. Algo quântico é simplesmente algo quantificável em algum valor ou grandeza escalar com precisão (quantum é Latim para quanto, afinal): um fóton é uma unidade (minúscula, mas quantificável) de luz, elétrons compõem átomos de forma previsível, e as "unidades de Planck" podem ser usadas para medir essas coisas. Física quântica é a teoria que descreve as coisas usando essas quantificações mais elementares nas menores escalas possíveis. Existe também uma coisa muito legal que é usada como o princípio de computação quântica digital, o conceito de entrelaçamento:
"Entrelaçamento quântico é um fenômeno físico que ocorre quando pares ou grupos de partículas são gerados, integram ou compartilham de proximidade espacial de formas que o estado quântico de cada partícula não pode ser descrito independentemente do estado das outras, até mesmo quando essas partículas estejam separadas por uma grande distância." - Wikipedia
Falar de relação entre partículas individuais e a correlação entre o estado delas é um pesadelo, e por isso que esse tipo de ciência é, no linguajar popular, "coisa de doido". Então vamos falar da ciência que trabalhamos no dia-a-dia, a ciência da computação que não poderia deixar por menos em adotar isso em escala menos complicada porém mais macarrônica. Pense em um sistema distribuído, daqueles que diversas aplicações co-existem e se integram. Duas aplicações. Três. E crescendo.
A cada novo elemento adicionado, o potencial de complexidade aumenta dramaticamente.

A satisfação de dependências entre diversas aplicações em um sistema distribuído é algo que escala geometricamente em complexidade a medida que integrações e componentes vão aparecendo. Se um pré-requisito (e.g.: uma API com um retorno conhecido) não estiver presente onde ela deveria estar, não precisa se entender dos mistérios do universo para saber que aquele pedaço do sistema está quebrado. A imagem acima é um pouco tendenciosa, porque assume que todos os elementos de um sistema conversam entre si e da mesma forma. Na prática as coisas ficam um pouco piores já que nem todo mundo se conversa mas podem conversar de formas diferentes. Você acaba com um grafo direcionado:
Diferentes formas de integração podem co-existir. E sempre tem aquele Simple Object Access Protocol que de simples não tem nada.

E até a técnica de construção de uma aplicação implica nesta complexidade. Foi declarada guerra aos monolitos: aplicações construídas embarcando em um único executável ou grupo de arquivos todas as funcionalidades de um sistema. Curiosamente, monolitos eram moda até uns anos atrás. Um tema recorrente em desenvolvimento de software, e que vou reiterar várias vezes é que toda hora há uma nova melhor prática.
As vantagens de um monolito é que todo o código está no mesmo lugar, dessa forma não se precisa recorrer a recursos arcanos de integração. O problema de um monolito é que, para arrumar uma porcariazinha qualquer nas entranhas dele é uma parte da aplicação toda que é impactada, e em casos mais extremos, re-escrita. Publicação? Você vai precisar mover a estante inteira, não apenas o livro que você quer trocar de lugar.
A vantagem de serviços menores é que com eles devidamente distribuídos e independentemente publicados, uma correção pode ser realizada de forma a causar pouco impacto, e melhor ainda com uma estratégia de blue-green deployment em que uma infraestrutura paralela de instâncias de aplicação é criada, e o tráfego pode ser roteado para elas quando elas estiverem prontas, minimizando ou até mesmo não tendo indisponibilidade da aplicação e, convenhamos, embora seja perfeitamente possível fazer o mesmo com um servidor com oito aplicações e 16 gigabytes de memória é melhor negócio e bem mais rápido subir duas instâncias de uma mesma aplicação pequena sem precisar mexer em mais nada. Com uma arquitetura realmente distribuída e com serviços pequenos e contidos, você pode publicar a hora que quiser. O problema de micro-serviços é que, a medida que as coisas são distribuídas, a complexidade de gerenciar eles pode aumentar e atingir níveis ridículos.
Não é um ouriço flertando com um globo terrestre. São gráficos da rede de micro-serviços e integrações para a Amazon e a Netflix.

Dois mundos. Ainda assim, o melhor de ambos parece ser algo inalcançável e o pior deles é uma assombração que se materializa nos piores momentos possíveis. O tempo todo temos uma nova melhor prática em desenvolvimento de software. Mas, e depois que o tempo passa, e a antiga melhor prática passa a ser não mais a melhor mas seus bastardos estão em produção e rendendo dinheiro mas precisando de manutenção, qual o choque de realidade com novas melhores práticas sendo que já temos um emaranhado de integrações entre aplicações construídas das mais variadas formas?
Engenharia e Engenhosidade
Lunch atop a Skyscraper, autoria não confirmada, publicada na edição de 2 de outubro de 1932 do New York Herald Tribune

A foto icônica dos operários comendo seu almoço em uma viga de aço a ~250 metros do chão durante a construção do Rockefeller Center em Manhattan levanta alguns questionamentos. Sabe-se que ela foi encenada. Sabe-se também que na época, segurança no trabalho não era tão séria quanto hoje: apenas em 1937 durante a construção da Golden Gate Bridge na Baía de San Francisco que se começou a se considerar segurança no trabalho como algo obrigatório, como disse o engenheiro responsável Joseph Strauss:
"Na ponte Golden Gate, nós tínhamos a idéia que poderíamos trapacear a morte provendo aos trabalhadores todo recurso de segurança conhecido. Para a irritação dos audaciosos que adoravam fazer acrobacias no final dos cabos, no meio do ar, nós mandávamos embora qualquer homem pego fazendo gracinhas no trabalho." - Golden Gate Bridge dot Org
O que traz uma discussão perturbadora: como as pessoas trabalham em desenovlvimento de software? Há quem defenda que é uma linha de produção ou de construção civil, em que um arquiteto ou engenheiro define algo a ser implementado e uma linha operária é responsável pelo trabalho braçal. Se via muito na época de plataformas de Rapid Application Development (RAD) que assumia que a implementação poderia ser feita por pessoas com baixa capacidade técnica, contanto que houvessem ferramentas suficientemente fáceis de usar ao alcance deles. Uma abordagem diferente foram as linguagens de quarta geração, que procuravam integrar em uma única plataforma a camada de apresentação e o acesso a persistência de dados. Hoje em dia são moda as plataformas de desenvolvimento low code (ou até mesmo no code) para implementação de regras de negócio mais simples. Economicamente, essas abordagens fazem sentido, com o custo de licença de uma plataforma de desenvolvimento ou um framework de mercado sendo amortizado por uma prototipação e entrega mais rápida de uma solução. Ao custo de dependência de um fornecedor e extensibilidade controversa do produto gerado: implementar uma tela do bom e velho Create/Replace/Update/Delete pode ser fácil, mas fazer qualquer coisa mais complicada que isso a sigla torna-se Cursing/Redoing/Undoing/Doing it all over again in some other way.
Tivemos também algumas idéias piores como geração de código. Na teoria, uma plataforma gera toda uma estrutura de código-fonte pré-definida, quem sabe até mapeada a partir de um diagrama BPMN ou de entidade-relacionamento. Com manutenibilidade no mínimo duvidosa logo depois, especialmente quando dependendo da implementação de algo mais complexo em cima do que é criado e onde inevitavelmente se acaba "pondo a mão na massa". Não confundir geração de código com todas as formas de scaffolding, que é um nome para várias técnicas, entre elas a padronização de repositórios como a praticada pelo gerenciador de pacotes da linguagem Rust, o Cargo, que com cargo init uma estrutura padrão de diretórios e um repositório git é inicializado em um formato recomendado; ou runtime scaffolding em orientação a objetos em que uma classe pode ser decorada para já prover alguns métodos ou interfaces que ela precisaria ter como os getters e setters cretinos que não fazem nada de especial mas são obrigatórios; sem efetivamente escrever o código deles.
Uma outra linha de pensamento ainda é a de software artesanal. Promotores dele pregam que software deve ser construído usando-se de engenhosidade e especialização e não apenas uma abordagem de linha de produção; remetendo a um processo mais artesanal porém direcionado para resolução de um problema com excelência técnica e uma abordagem direcionada. Código direcionado e otimizado é definitivamente melhor para a pastilha de silício que vai fazer o trabalho sujo, mas se todos os envolvidos na manutenção do código-fonte (e, especialmente, o felizardo responsável por manter a codebase depois) não tiverem um bom conhecimento do que está sendo feito, funcionalidades acabam centralizadas em pessoas específicas, e cada vez mais o código fica mais especializado (senão críptico).
Frameworks prometem unir o útil ao agradável. Ao incorporar muita coisa complicada como geração de camadas de apresentação, facilitar integrações e abstrair toda a persistência o desenvolvedor pode focar em resolver o problema. Frameworks porém se não tiverem um escopo bem definido e disciplina na sua evolução tendem a ir crescendo de forma desordenada e incorporando soluções para os problemas mais exóticos e criando cada vez mais abstrações e wrappers e interfaces e se acaba com um amontoado de funcionalidades e conceitos que podem não fazer muito sentido por si só em cima da plataforma da linguagem. No fim, a pastilha de silício do parágrafo anterior acaba soterrada.
Pelo menos o programador fica livre para atacar o problema.
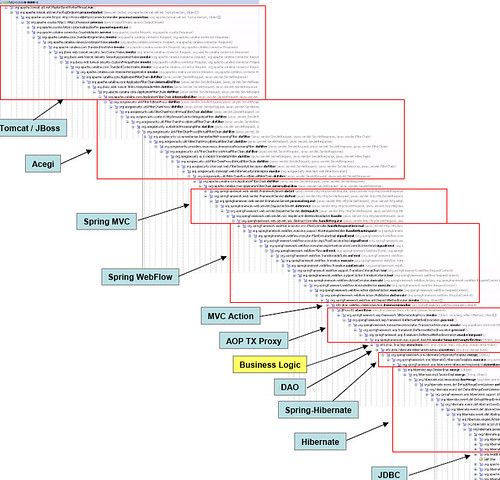
Indiferente da forma utilizada, é fato que a melhor prática de hoje não vai ser a melhor prática de amanhã. Inevitavelmente a codebase gerada por programadores heroicos defendendendo um estilo artesanal vai ser impossível de manter se não for devidamente documentada; a codebase feita pelo pragmatismo de um framework vai precisar da manutenção não apenas do código mas também do maquinário dele; a codebase feita na linha de produção com um mínimo de esforço em cima de uma plataforma que promete muita coisa não precisa de muita manutenção no próprio código mas essa plataforma tende a ser pesada, complexa e inaplicável a problemas especializados (e a custar mais para ser mantida). O ponto é, aplicações precisam ser acompanhadas constantemente o tempo todo: correção de bugs, mitigação de vulnerabilidades, atendimento de novas demandas. Mas é justamente este último item que parece ser priorizado hoje em dia.
Se um prédio é feito com areia ou um avião é montado prendendo a fuselagem com chiclete, eles caem, pessoas morrem, engenheiros vão presos e se aprende com as lições dos erros de projeto em toda a indústria. Se um software acaba ruindo, não necessariamente alguém morre mas definitivamente alguém fica condenado a fazer tudo funcionar de novo em um ciclo interminável de busca de soluções para resolução de problemas enquanto tudo é mantido atualizado.
Quando se vê, a equipe de desenvolvimento está trabalhando em altura sem o equipamento de segurança e sem condições de tornar a sua obra mais segura.
Uma onda de coisas para fazer
弾幕, literalmente japonês para "barragem" mas melhor conhecido em inglês como bullet hell (inferno de balas) é um estilo de jogos de videogame baseado nos Shoot'em up!, nos quais normalmente se assume o controle de uma nave espacial em um nível com vários inimigos e após uma troca de tiros com todos eles ao longo de um trajeto percorrido (e com obstáculos) no final se chega em um "chefe" que precisa ser atingido muitas vezes para ser derrotado, e usando estratégias específicas. O diferencial do bullet hell é que são muitos inimigos lançando muitos projeteis em muitos padrões de ataque difíceis de memorizar. Ah, e a tela vai andando sozinha e empurrando você para cima da confusão.
Ikaruga (2001), no Dreamcast, incorpora uma mecânica com inimigos e projéteis de duas cores e a inversão da polaridade da nave do jogador para absorver projéteis de uma cor e causar dano em inimigos da cor oposta.

A fila anda, e em uma necessidade de faturamento novas demandas de desenvolvimento vão sendo encaixadas uma atrás da outra querendo agregar o cobiçado "valor ao produto". O ritual das metodologias ágeis é um mantra: um product owner preenche um backlog com a descrição das coisas que ele deseja e em periódicas celebrações o time de desenvolvimento e ele se reúnem para estimar o tempo que cada coisa levaria (observe a conjugação) para ser construída e com as demandas priorizadas, todos vão ao trabalho e após uma, duas, quatro semanas o resultado é apresentado. Enxágue e repita.
Um problema endêmico de qualquer coisa que exija estimativas é que em muitos casos em sistemas grandes apenas se conhece o tamanho do problema quando se está frente-a-frente com ele: uma funcionalidade de impressão de documentos pode ser algo simples e implementado em algumas horas (gerar uma página e media: print nela) como pode levar alguns dias (integrar com serviços como Google Cloud Print) como pode levar meses (integrar com um sistema de auditoria de impressões com aprovações e inserção de steganografia customizada em cada documento). Estimativas tem que contar com possíveis supresas no meio do caminho, como o requisito de uma fonte (tipográfica) no documento gerado que pode precisar de licenciamento ou a integração com o sistema de auditoria que por alguma razão apenas funciona se for feita usando um XML com quebras de linha de Windows. E isso compromete ainda mais quando se trabalha em sistemas maiores com equipes grandes, ou várias equipes:
"Essa é uma das razões porque desenvolvedores realmente detestam ter que colocar números em tarefas. Isso se torna um problema maior quando os desenvolvedores precisam integrar esforços com outros desenvolvedores, especialmente em componentes desenvolvidos ao mesmo tempo. Se houver uma divergência impeditiva entre a interação de dois componentes, refazer esses pedaços pode levar tempo e ter complexidade que são difíceis de medir.
Isso também sugere que Ágil não escala bem. Dependências de integração normalmente não são rastreadas (ou são agrupadas em estórias hierárquicas), e ainda assim tendem a ser um dos aspectos mais críticos de desenvolvimento de software.
Realisticamente, isso não é tanto um problema do Ágil como é com ferramentas comuns. Tecnicamente falando, um diagrama de projetos é um grafo, não apenas uma árvore. Você tem dependências de espaço, tempo, organização, abstração e complexidade, e estimar tempo para complexidade é muitas vezes o elo mais fraco entre essas ferramentas. Do outro lado esse esforço é muitas vezes piorado quando você tem pessoas demais envolvidas nos projetos, porque a complexidade de gerenciá-los aumenta geometricamente com o tempo."
- The End of Agile - Forbes Cognitive World
Software também não é uma construção que uma vez concluída pode ser esquecida na esperança que tudo continue funcionando. Vulnerabilidades de segurança são identificadas frequentemente, às vezes em software de terceiros, raramente em coisa que pode estar envolvida com todo software como nós o conhecemos e exigir uma atualização de pacotes no sistema operacional ou uma intervenção maior desde um rebuild da aplicação com dependências atualizadas até a re-escrita de um trecho dela, do contrário algo pode dar muito errado. Naturalmente, os seus usuários são seus maiores aliados ao encontrar problemas, seja aquele bug ocasional da etiqueta do campo que some se você clicar 17 vezes no canto inferior esquerdo da tela porque tem um bug do Edge com CSS3, ou seja o incidente que tirou o sistema do ar quando alguém anexou um arquivo XML sem fechar o documento com a tag </xml> no final. Todas essas demandas aparecem independente de você querer ou não, apenas em escala maior ou menor dependendo de quantas pessoas usam seu software e de um jeito ou de outro elas vão precisar ser arrumadas. A menos que você possa se dar ao luxo de chamar bugs de features (não, você não pode).
É importante ter uma codebase fácil de manter e toda uma infraestrutura de apoio com integração e entrega contínua, testes automatizados e facilidade de publicação. Mas mais importante que isso é o tempo disponível para a equipe poder trabalhar em demandas de melhoria para manter a casa em ordem; o que é mais fácil dito que feito dependendo da organização: apenas com a entrega de novos itens de backlog se pode aumentar o faturamento e manter o desenvolvimento rentável. Ao mesmo tempo um débito técnico que é iniciado com a construção de qualquer coisa (e às vezes apenas pelo fato de se construir a coisa ...) começa a contar e a render juros. Cada nova decisão tomada para entregar alguma coisa rápido em detrimento de manutenibilidade a longo prazo aumenta essa dívida e assim como qualquer outra, eventualmente ela é cobrada de alguma forma.
A tela vai continuar andando, e os tiros vindo. Não exatamente um bullet hell, mas não deixando de ser infernal.
Uma enorme coreografia
Muita controvérsia rodeia a Coréia do Norte, mas um recorde inesperado é o da maior apresentação de ginástica já realizada: em uma das apresentações do Festival de Arirang houveram 100090 participantes, ou gente demais para se organizar facilmente. Mesmo que a grande maioria dos integrantes tenha apenas a ação de mostrar uma placa com algumas cores (servindo efetivamente como um pixel humano), a coordenação necessária é extraordinária, e é como se fossem todos orquestrados para dentro do ritmo, cada um funcionando como uma pequena parte de um mecanismo ridiculamente complexo, senão um organismo vivo.
"Jogos Coletivos de Arirang", Coréia do Norte, com detalhe dos participantes que ficam ao fundo.

Em software às vezes empacotamos coisas em releases, ou um conjunto de coisas a serem entregues juntas. Hoje mais conhecidas como big-bang releases: ao longo de um ciclo de desenvolvimento várias novas funcionalidades são criadas mas são apenas entregues (ou, colocadas em produção) quando tudo estiver pronto e o product owner satisfeito. Assume-se um balé coreografado com uma equipe entregando graciosamente o que a outra precisa na hora em que ela precisa. E quando uma delas tropeça é preciso usar-se de artifícios mais esquisitos de improviso para a orquestra não parar.
"Nós também costumávamos empacotar cinco ou seis novas grandes funcionalidades em uma release big-bang ao invés de entregar cada nova melhoria assim que pronta. Isso causa uma grande impressão, mas releases big-bang empacotam o risco de todos os componentes, então se uma delas fica para trás, o pacote todo fica preso. O que sempre acontece. Então você acaba com um risco muito maior de ter uma entrega significativamente atrasada ou, no pior caso, tendo que voltar atrás com tudo.
Jogar fora um pouco de trabalho, simplesmente pela forma que você trabalhou nele, é um soco moral no seu estômago. Mas é o que acontece quando o seu trabalho está tomado por dependências.
Hoje nós entregamos as coisas quando elas estiverem prontas ao invés de coordená-las. Se estiver pronto para a web, implanta! iOS vai ter isso quando estiver pronto. Ou se for o iOS primeiro, Android vai ter também quando eles chegarem lá. O mesmo é válido para a web. O seu cliente vai ter o ganho de valor quando isso estiver pronto em qualquer lugar, não quando isso estiver entregue em todo lugar.
Então não amarre mais nós, mas corte mais amarrações. Quanto menos laços, melhor."
It doesn't have to be crazy at work; David Heinemeier Hansson & Jason Fried; Harper Business, 2018
Correr todos os riscos de várias implantações juntas é complicado, mas dependendo de como está sendo praticada uma abordagem agile para um projeto, se acaba amarrando uma entrega na outra e no final não se consegue fugir de uma coreografia dessas. Pode piorar, ainda, dependendo da infraestrutura usada: se você tem servidores de aplicação à moda antiga, pode ser necessário parar tudo para atualizar o que é necessário, e o que permanece inalterado mas tem dependências de integração acabe não quebrando. Se você usa-se de algum conceito mais abstrato de servidores de aplicação (e.g.: immutable servers) você vai precisar ter infraestruturas paralelas para os seus testes de integração e regressão. Se você não roda as aplicações em servidores, mas em containers (e.g.: Kubernetes, Nomad) ou ainda plataformas serverless (e.g.: Google App Engine ou Heroku) as coisas ficam mais fáceis de serem implantadas e entregues. E ainda assim a gente acaba com uma mistura dos três, e torna-se complicado adaptar qualquer aplicação para essa realidade.
Desenvolvedores tendem a não pensar também em fazer as aplicações se comportarem de forma resiliente. É uma mudança de paradigma, imaginar que servidores de aplicação podem cair, manutenções de emergência podem ser realizadas, ou aquela controladora RAID pode não se comportar como planejado quando um dos discos pifar e subitamente um kernel panic tirar uma instância de aplicação do ar. Que o diga um banco de dados engargalado, um serviço de terceiros que muda subitamente o formato da resposta, ou um cabo de rede cortado. As coisas vão dar errado cedo ou tarde, e as aplicações precisam tratar adequadamente também esse tipo de problema ao invés de repassar categoricamente os erros como se fossem batatas quentes na apresentação de dança do jardim de infância.
O trabalho em equipe em um sistema distribuído é um exercício de confiança: não apenas confiança que as coisas vão estar funcionando quando se precisar delas, mas também confiança que quando não estiverem elas serão adequadamente tratadas e nada vai estourar na cara do usuário final ou que informação importante não vai sumir no limbo. Quando se entrega um lote enorme de funcionalidades e novas integrações e novos recursos, ocasionalmente meses depois da sua construção, são todas essas pequenas coisas que podem dar os mais aleatórios problemas que são difíceis de se prever e mapear.
O que deveria ser um casal fazendo patinação artística com movimentos graciosamente ensaiados e confidentemente executados torna-se um desfile militar coordenado entre milhares de integrantes onde ninguém pode dar um passo em falso, e apenas o medo de algo dar errado e quebrar o ritmo do bloco inteiro é capaz de manter tudo na linha.
E o que dá pra fazer?
Eu definitivamente pintei um quadro sombrio em tudo que escrevi até aqui. A realidade de viver rodeado por desespero no dia-a-dia não é algo estranho para muitos de nós, então é hora de todos respirarmos fundo e contarmos juntos e pausadamente até dez, enquanto pensamos em como fugir desse emaranhado de complexidade no qual nos metemos.
Reme junto
"Digamos que somos um monte de pessoas em um navio e tem um monte de buracos no navio e nós somos muito bons em em tirar água da nossa seção e nós inventamos um balde muito bom. Seria tolice de nossa parte não compartilhar o projeto desse balde. Porque se o navio afundar, nós afundamos junto dele."
Elon Musk, sobre a abertura de algumas de suas patentes
Talvez você esteja como parte de um sistema distribuído mas não sofra destes problemas. E quem sabe você não vive em uma realidade paralela de todo mundo. Porque não ajudar os seus coleguinhas? Algo você está fazendo muito certo.
Mantenha a casa em ordem
O maior pesadelo em uma oficina é as coisas estarem desorganizadas. Definitivamente não é legal as ferramentas estarem soltas em cima da serra de bancada, muito menos deixar tudo sujo de graxa de um dia para o outro. Apenas com disciplina e organização, e a priorização de manter as ferramentas afiadas e o ambiente limpo, se consegue trabalhar com eficiência e segurança.
O mesmo se aplica para infraestrutura de tecnologia da informação. Ter a bancada de trabalho limpa é pré-requisito para entregar software bem-feito. O amontoado de sujeira de software pode se manifestar de diversas formas, como código mal-feito, servidores de aplicação mal-configurados, rotinas repetitivas ou mesmo divergência grande entre ambientes (e, pior, desconhecimento da sua própria infraestrutura).
Por isso, mantenha estruturadas suas pipelines de integração e entrega contínua. Refatore o código para uma melhor manutenção, usando-se da regra do escoteiro de deixar o lugar mais limpo do que quando chegou. Invista em automação para evitar trabalho manual e por consequência sujeito a falhas. Tenha certeza que não tem coisas soltas nas suas instalações. E, especialmente, conheça todos os lugares onde sua aplicação vai estar, porque mesmo onde você não pode por a mão você pode sugerir melhores formas de trabalhar.
Normalize na simplicidade
"Simplicidade é pré-requisito para confiabilidade." - E. W. Dijkstra
"Tolos ignoram a complexidade. Pragmáticos sofrem com ela. Alguns conseguem escapar. Gênios a removem." - Alan Perlis
"Menos é mais." - Robert Browning
Nada é simples na ciência da computação, a menos que você fale assembly x86 e ARM fluentemente, porque daí você vai ver um monte de rodeios e metáforas tão desconexas que você vai ser perguntar se não passou a enxergar uma nova dimensão temporal. O uso de baixo nível computacional para a resolução de problemas é complicado porque o seu código fica mais próximo da máquina, e mais distante dos humanos.
Paradigmas abstratos demais que aproximem os problemas do domínio comum humano também são um problema, por causa de todas as dependências que se precisam ter por debaixo do pano para tudo funcionar. O que fica parecendo ser simples e na verdade está acionando dezenas de camadas de abstração sem você saber é um problema em potencial quando inevitavelmente algo nas entranhas da plataforma de aplicação não funcionar (ou você não tiver dinheiro para pagar a licença dela ...).
O fato é que será necessário escrever código hora ou outra, e fazer algo simples é complicado. Se demoniza muitas más práticas e se louva o Uncle Bob e sua Palavra, o livro Clean Code e tudo que ele inspirou.
Um passo-a-passo mais prático e direcionado é se perguntar antes de escrever qualquer novo código:
- Sou o único que possui esse problema bem específico, e não tem uma solução pronta e simples que eu possa integrar aqui?
- Realmente preciso implementar essa funcionalidade? Porque? De fato é o que é necessário para eu atender ao requisito que estou executando?
- Algo que eu tenho pronto já pode ser reutilizado? Ou, ao fazer isso, não estou introduzindo redundância ou duplicação?
- Estou fazendo algo simples e legível? Não estou fazendo procedimentos técnicos alternativos?
- Eu vou entender isso daqui dois anos? Outras pessoas conseguem entender também?
- Tem como testar? De forma integrada? Minimizando as chances de quebrar algo?
Deve-se perseguir código simples, legível e sem muitas dependências esotéricas.
$ python -m this
The Zen of Python, by Tim Peters
Beautiful is better than ugly.
Explicit is better than implicit.
Simple is better than complex.
Complex is better than complicated.
Flat is better than nested.
Sparse is better than dense.
Readability counts.
...
Entregue mais
"No mundo da entrega contínua, lançar novas funcionalidades não é um evento que sacode tudo onde todos na empresa param de trabalhar por semanas após um congelamento de código e esperam nervosamente em volta de painéis durante os fatídicos minutos de publicação. Ao invés disso, lançar novo software para os usuários deve ser tão rotineiro, chato e fácil que pode acontecer várias vezes no dia."
É fato que podemos estar amarrados em uma arquitetura de monolitos em servidores mutáveis que precisam ser mantidos. É o equivalente a trocar o óleo do carro: não tem como fazer com o motor ligado. Que o diga a revisão que envolve ver bateria, filtro de ar, suspensão e freios.
Por isso que hoje em dia está se promovendo a migração para outras plataformas, possibilitando publicações sem indisponibilidade subindo as novas instâncias de aplicação em paralelo, e roteando todo o tráfego para elas quando elas estiverem prontas. Ao invés de você se dar ao trabalho de ter um carro, passe a usar Uber para tudo: para cada nova corrida é um motorista e um carro diferente, mas você chegou onde precisava e não tem mais a responsabilidade de manutenção dele.
Lógico, você pode chamar um Uber para um carro levar você, alguns amigos e alguma bagagem, não para uma carreta de 12 eixos levar sua mudança (pelo menos ainda). A inércia de rotear o tráfego entre monolitos é mais complexa que fazê-lo entre serviços menores.
Migrando para este tipo de infraestrutura é uma tarefa visivelmente mais complexa, dependendo de conceitos abstratos e modernos que definitivamente vai se precisar promover uma mudança de cultura (senão qualificação técnica). Ao troco de tranquilidade em poder fazer publicações de forma mais independente e transparente.
Mas mesmo que não seja possível uma revisão completa de infraestrutura e de arquitetura, pelo menos uma mudança na forma de trabalho pode ser iniciada. Ao invés de aguardar uma conclusão de release, implante antes. Salvo os casos macarrônicos que definitivamente não são todas as entregas de funcionalidades, não tem porque ficar com recurso de software em estoque. Enquanto ele está guardado, nada acontece, mas nas mãos de seu usuário que o real valor se manifesta.
Monitore tudo
Um servidor tem muita coisa para te falar, mas com palavras não sabe dizer. Bytes transmitidos pelas interfaces de rede, system load, processos, uptime, ... mas, nessa infinidade de números, o que pode fazer sentido? Claro, um pico de CPU durando muito tempo, baixo espaço livre em disco, uso constante de swap são claros indicativos de problemas, mas problemas podem começar muito antes.
A plataforma de aplicação pode fornecer suas insights também. Uma Java Virtual Machine já monitora nativamente o número de threads em andamento, o consumo interno de memória, a frequência de garbage collection ou mesmo coisas esotéricas de número de conexões em aberto com bancos de dados ou sockets TCP.
Mas o melhor tipo de métrica que se pode coletar é sobre seu negócio. Quantos usuários estão logando, quanto tempo cada login está levando, quantas autenticações estão acontecendo com erro. Quantos relatórios estão sendo gerados, quanto tempo é gasto em cada passo de geração como acesso a dados e renderização, quantos relatórios estão mandando gerar e após sua aplicação dividir águas para gerá-los acabam não vistos? Sabendo como o seu sistema se comporta normalmente, análises podem ser realizadas em tempo real para identificar comportamentos fora do padrão, e a prevenção de um incidente ou uma indisponibilidade: se um webservice remoto passa a levar mais tempo para responder, é previsível que mais chamadas do lado de cá vão ser enfileiradas, e isso vai sobrecarregar ainda mais a ponta de lá. Antes de iniciarmos uma retry storm que vai quebrar ele, podemos intervir para ver qual é esse problema superficial e, efetivamente, apagar a bituca de cigarro antes que ela vire um incêndio na floresta.
Diversas plataformas podem ser configuradas para avisar ou dependendo do caso até executar uma ação automatizada onde o problema foi identificado.
Três painéis, três tipos de métricas. A Organização Européia para Pesquisa Nuclear disponibiliza métricas de rede para escovadores de bit. O projeto de métricas da Rede Tor oferece uma visualização sobre sua utilização mostrando tráfego na rede toda, números de hidden services hospedados e até estatísticas de uso por países onde censura é circunavegada por ela. A Wikimedia, organização responsável pela revolução no compartilhamento de conhecimento, expõe métricas de uso de suas plataformas publicamente com informações de edições por minuto ou artigos fornecidos.
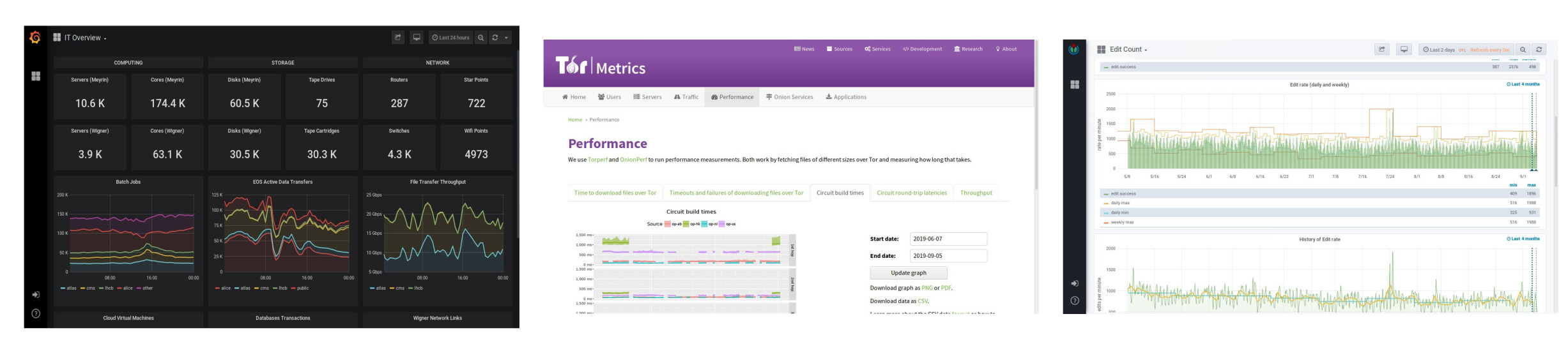
Automatize suas respostas à monitoração
Em 2016, ao longo de um final de semana, ocorreu um assalto ao Banco Central de Bangladesh e 81 milhões de dólares foram roubados. Diferentemente de um grupo encapuzado e armado chutando a porta do prédio, a única invasão foi online. Os criminosos conseguiram, antecipadamente, invadir a rede da instituição, e observar como as transações eram realizadas através da rede SWIFT, usada por instituições financeiras do mundo todo para transferência de dinheiro, normalmente em quantias altas. Com o conhecimento da rede, das credenciais do Banco Central de Bangladesh e dos hábitos de transferências, um esquema foi traçado para realizar as transações fraudulantas nos dias 4 e 5 de fevereiro de 2016, uma quinta e uma sexta nas quais é o Sabá em Bangladesh e não há expediente. Várias transações foram enviadas ao Banco da Reserva Federal de Nova Iorque, autorizando a transferência de US$951M para contas nas Filipinas e Sri Lanka, mas o sistema automatizado do lado dos Estados Unidos marcou trinta das transações (em um total de US$851M) para revisão, enquanto repassou US$20M para contas no Sri Lanka (que depois foram recuperados) e outros US$81M para as Filipinas, onde é praticado o final de semana ocidental e os bancos de lá não deram uma resposta a tempo, o dinheiro foi sacado das contas dos laranjas e posteriormente lavado. O que levou o sistema do banco norte-americano a classificar a maior parte das transações como problemáticas e evitar um roubo ainda maior? Ao invés de foundation, algumas transações tinham como destinatário uma fandation.
Um sistema precisa ser auto-suficiente e precisa saber se comportar em um evento de monitoração, e a resposta a eventos, sejam ataques por pessoas mal-intencionadas ou falhas causadas por colegas bem intencionados, precisam gerar uma notificação. Do contrário, no feriado prolongado com quase todo mundo na praia e os colegas responsáveis pela monitoração presos no hospital com a intoxicação alimentar contraída de última hora é que o desastre vai acontecer, seja porque alguém aprendeu seus hábitos e sabe que você está mais vulnerável com a segurança; seja porque Murphy é nosso pastor e algo nos faltará.
Você aceita nosso senhor e salvador, Caos?
Chaos Engineering é uma disciplina com uma premissa interessante: conduzir experimentos em um sistema para se adquirir confiança na capacidade dele em resistir condições turbulentas em produção. O termo vem de Chaos Theory, o estudo de sistemas sensíveis às condições iniciais que podem mudar completamente de estado se um pequeno evento estiver relacionado profundamente em seu comporamento. Provavelmente deve ser familiar: se uma borboleta batendo as asas na Amazônia poderia (novamente, atente a conjugação) causar um furacão no Texas, definitivamente um roteamento zoneado na sua rede pode quebrar o seu sistema todo.
Assumindo que estamos sujeitos a caos rotineiramente, passamos a construir aplicações capazes de sobreviver a estas situações. Se o negócio permitir, quando um banco de dados cair, não tem porque propagar isso entre serviços, mas pode ser retornado algo que já se tenha em cache (mesmo que frio). Se uma dependência de serviço não estiver retornando uma resposta adequada, obrigatoriamente esse erro tem que ser propagado até estourar na cara do usuário? Ok, algumas coisas são realmente impeditivas, mas existem mecanismos para impedir uma sobrecarga ainda pior, entre eles o paradigma de circuit breaker, ou (literalmente) um disjuntor: quando uma sobrecarga elétrica acontece em sua casa, normalmente o herói é aquela caixinha estranha que fica escondida em um painel elétrico e é responsável por detectar a anomalia e desligar tudo que esteja ligado nela, impedindo que dano maior seja causado em todos os seus aparelhos elétricos; e quando tudo volta ao normal você o liga novamente. Computacionalmente não é muito diferente: na sua camada de persistência pode ocorrer de uma enxurrada de conexões ao banco de dados falharem. Não faz sentido ficar sobrecarregando sua infraestrutura com tentativas de reconexão, logo, sua aplicação pode guardar um estado de conectividade quebrada e, em caso de problemas, retornar uma resposta mais adequada ao invés de lidar diretamente com erros de baixo nível. Naturalmente, criando um evento de monitoração sinalizando problema para alguém olhar de perto. Melhor ainda, o seu disjuntor pode ser re-estabelecido automaticamente: verifique isolada e periodicamente se as coisas voltaram a funcionar, e então volte a trabalhar normalmente após o problema for detectado. Essas estratégias de contorno devem estar bem definidas em um sistema distribuído.
Uma vez que seu sistema esteja confiavelmente estruturado para lidar com situações de falha, é interessante conduzir experimentos periódicos para garantir seu funcionamento, e experimentos de Chaos Engineering se dividem, essencialmente, em duas categorias:
- Infrastructure faults (e.g.: Chaos Toolkit, Mangle) : com ferramentas que se conectam diretamente à sua infraestrutura, você pode simular os inevitáveis problemas. Sabendo que seu cluster Elasticsearch é distribuído por uma razão, porque não puxar o cabo do master e ver o que acontece? Espera-se que algum outro nó assuma suas funções, e se você está usando um balanceador adequado, então tudo ocorre de forma transparente para as aplicações. Igualmente para uma instância de aplicação, ou para um banco de dados, ou mesmo uma região inteira de datacenters. Se sua aplicação é construída pensando nisso, não tem porque ter medo. A maior vantagem deste tipo de abordagem é que existem muitas ferramentas prontas para serem colocadas na sua infraestrutura e elas não precisam conhecer sua aplicação, mas apenas os detalhes de topologia que você queira testar.
- Failure injection (e.g.: Netflix FIT) : uma forma mais sofisticada de induzir falhas mais sutis nas aplicações, desenvolvida na Netflix, a metodologia de injeção de falhas é feita diretamente nas aplicações usando facilidades das plataformas usadas por eles (das quais, quase tudo é software livre) de forma a simular falhas de alto nível, como latência de rede, ou retornos inválidos de integrações, ou timeouts em serviços; e então esses pontos de falha simulados são agregados na Chaos Automation Platform, ou ChAP, que é responsável por simular a ocorrência destas falhas. Interessantemente com este modelo de injeção de falhas, é possível testar em apenas parte do tráfego de sua aplicação usando uma amostragem pequena, com um grupo de controle, e validação de métricas que mostrem se o negócio está sendo comprometido ou se a sua arquitetura é de fato resiliente. Uma vez que se tenham dados desses experimentos é possível realizar correlacionamentos entre ocorrências, ou inferir melhorias em parâmetros de aplicações como número de threads ou timeouts ou uso de memória. O próprio ChAP possui um módulo chamado Monocle que coleta esse tipo de informação e mostra observações em cima delas. Embora isso tudo seja integrado às plataformas da Netflix, essa funcionalidade é perfeitamente replicável usando Prometheus e criatividade.
Uma vez que as aplicações estejam devidamente resilientes e prontas para o inevitável e esse tipo de coisa esteja funcionando bem, porque não conduzir estes experimentos de Chaos Engineering em produção? É um exercício de confiança, que requer maturidade, e instrumentação, e monitoração, e uma abordagem seletiva, mas, antes isso acontecer no meio do expediente em uma situação controlada com todo mundo olhando de suas estações de batalha prontos para a ação, ao invés de tudo começar a rolar ladeira abaixo em uma madrugada de natal. Cada vez mais e mais esse tipo de iniciativa vem ocorrendo em vários serviços muito populares na Web, mas o berço é a infraestrutura da Netflix e, cá entre nós, quando foi a última vez que você não conseguiu assistir Friends pela 37ª vez porque a Netflix estava fora?
Livre-se das rédeas e dos chicotes
Pró-atividade em manutenção de soluções é algo que deve ser incentivado, motivado, esperado de times de desenvolvimento. Se uma ação em cima da codebase ou da infraestrutura pode agregar valor e se o esforço é baixo, ela deve ser realizada. Ainda assim não são estranhas as situações em que alguém precisa assinar embaixo, afinal, manda quem pode.
"Porque gostamos tanto de processos? Eles oferecem uma forma de medir progresso e produtividade, o que faz as pessoas se sentirem mais eficientes e responsáveis. Quando usados corretamente, processos devem padronizar e simplificar as tarefas necessárias que mantém o negócio funcionando tranquilamente. Eles devem permitir que as organizações executem trabalho complexo, particularmente a medida que uma organização cresce. Relatórios de gastos, por exemplo,devem ter um processo que cada empregado siga toda vez - isso é bom senso. Processos inteligentes encapsulam um pacote de conhecimento organizacional. E isso é uma coisa boa.
Mas não é uma coisa boa quando tem tantos processos que eles acabam contendo as pessoas que eles devem ajudar. Se sua equipe passa os dias pedindo por permissão antes de executar, levando uma hora para fazer relatórios de gastos ou folhas de ponto, participando de reuniões redundantes, ou respondendo e-mails irrelevantes, você tem um problema. Quando exatamente os empregados devem conseguir tempo para inovar quando toda tarefa ou tópico é marcado como "urgente" e todo prazo é ASAP? Alguma coisa vai precisar ceder, e essa coisa é parte do trabalho que eles estão empurrando para depois."
5 Ways Process Is Killing Your Productivity, Fast Company
Se processos estão para padronizar as coisas, padronize por algo fácil de trabalhar! Não faz sentido coisas que envolvam reuniões com dezenas de pessoas e longas threads de e-mails para uma luz verde. Não deve ser preciso uma assinatura do conselho de segurança das Nações Unidas para alguém poder tomar a iniciativa de arrumar algo.
A recíproca do As Soon As Possible é ainda pior. Sem uma forma estruturada de trabalho, o desespero e a histeria tomam conta. O telefone toca o tempo todo, e você se encontra com 20 mensagens não lidas de cada colega se levantar da cadeira para ir buscar um café, e por alguma razão todo mundo quer as coisas de imediato.
"Pare de falar ASAP. Nós entendemos. Está implícito. Todo mundo quer que as coisas fiquem prontas assim que elas possam ser feitas.
Quando você se transforma em um desses que adicionam ASAP ao final de cada pedido, você está dizendo que tudo tem alta prioridade. E quando tudo é de alta prioridade, nada é. (Engraçado como tudo tem a mais alta prioridade até que você tenha que priorizar de fato as coisas.)
ASAP é inflacionário. Desvaloriza qualquer pedido que não diga ASAP. Antes que você perceba, a única forma de concluir algo é colando um adesivo escrito ASAP.
A maioria das coisas não requer esse tipo de histeria. Se uma tarefa não ficar pronta neste mesmo instante, ninguém vai morrer. Ninguém vai ser demitido. Não vai custar uma fortuna à empresa. A única coisa que ficar apressando isso vai fazer é criar stress artificial, que vai levar a burnout ou coisa pior.
Então reserve o seu uso de linguagem de emergência para emergências de verdade. Do tipo que tenham consequências diretas e mensuráveis para a inação. Para todo o resto, se acalme."
Rework; David Heinemeier Hansson & Jason Fried; Crown Business, 2010
O desperdício de tempo deve ser evitado, seja causado por um processo mal-feito ou por uma corrida atrás do próprio rabo motivada por um desespero que não faz sentido em existir. Procure rever seus processos para ver se você mesmo está atendendo bem às pessoas que precisam de você, e ao mesmo tempo procure confiar nos colegas antes de interromper qualquer coisa que eles estejam fazendo porque você quer algo pronto agora.
Re-escreva
Muita gente se apega ao que constrói. É bom sentir orgulho daquilo que você faz, ver como uma obra de arte, imaginar que criou uma obra-prima da engenharia que vai poder ser mantida por muito tempo e se espera que seja idolatrada pelos seus usuários como um carro indestrutível que com um mínimo de manutenção permanece funcionando e é capaz de sobreviver a qualquer coisa e ser facilmente transformado, ou usado para várias outras coisas.
A verdade é que para o seu usuário final você está fornecendo uma ferramenta, e no melhor dos casos ele enxerga seu software como um produto bem construído mas que eventualmente ele vai precisar trocar (e.g.: design da Apple). No pior dos casos? Você pode até gostar do que fez, mas o seu usuário apenas é seu usuário porque é obrigado usar. Independente do caso, pode ser após dois ou vinte anos, seu software não vai mais ser moderno, ou fácil de manter, ou mesmo útil.
"O mundo do Ágil estava publicando livros como 'Refactoring'. Aqui estão todas as táticas e ferramentas que você pode usar para transformar qualquer coisa em qualquer outra coisa. E não só isso. Enquanto você está transformando essas coisas em outras coisas, se você estiver tendo problemas com elas, se isso doer, isso é débito técnico."
"Você fez um design ruim. Mas, não se preocupe. Temos como remediar. Nós temos cursos para você fazer, conferências para você ir, e livros para você ler onde você pode se redimir e descobrir como você falhou. Porque é sua culpa. Se o software é difícil de mudar, é sua culpa. Você é um programador ruim e tem que aprender a fazer melhor."
...
"Bom, isso foi porque nós começamos a não nos sentir bem ao trabalhar no BaseCamp. Nós não estávamos competindo com nossas melhores idéias. Nos estávamos competindo com nossas idéias de 2003. Aquele ano que nós falamos que foi logo após do estouro da bolha do dot-com. Aquele ano antes do AJAX e smartphones e todas aquelas outras coisas. Aquela foi a fundação para a formação de todas as nossas melhores idéias. E nós éramos tão arrogantes de pensar que as melhores idéias que tivemos em 2003 ainda seriam as melhores idéias em 2011?"
...
"E ultimamente nós decidimos que Louis C. K. estava certo. 'Há um grande desafio em não ter o seu espetáculo antigo', ele diz. Ele joga fora o seu roteiro todo ano. Mas eu acho que você pode se superar. Mas você não vai se superar se não tiver um vazio ali. Você tem que tirar o seu material antigo de você para poder fazer seu melhor trabalho. Você tem que ter o vazio ali. Isso é aterrorizante."
David Heinemeier Hansson, Rewrite!
Inevitavelmente a melhor prática de hoje não vai ser a melhor amanhã, e certamente no futuro vamos ter melhores ferramentas que hoje. Dez anos de existência para um software é uma eternidade e certamente vários problemas que eram resolvidos de uma forma na sua idealização são resolvidos de formas melhores hoje.
É sabedoria popular que em time que está ganhando não se mexe. Ao mesmo tempo, quando for hora de mexer porque o time começou a perder, o impulso é de se mexer o mínimo possível. Eventualmente faz mais sentido re-escrever. Recomeçar. Colocar novas idéias, novas ferramentas e novos conceitos em prática, mas não apenas porque são novos: porque eles aumentam o valor entregue e viabilizam a continuidade do negócio. Do contrário a concorrência vai usar as novas idéias dela e seu modelo tradicional vai por água abaixo.
Simplesmente trocar uma aplicação pela outra também é um problema. Como tudo está sendo feito do zero, é mandatório fazer as coisas co-existirem por um tempo para que as pessoas consigam conhecer a nova solução, e participar do desenvolvimento dela sugerindo o aperto do ocasional parafuso e tenham tempo para se adaptar.
Antes agora do que nunca
Telltale Games foi um estúdio responsável pela cultuada adaptação da série de TV The Walking Dead no jogo de 2012 que vendeu 28 milhões de episódios no mundo todo. O jogo The Walking Dead foi revolucionário no gênero point and click incorporando uma estrutura episódica e uma jogabilidade mais orientada às decisões tomadas pelo jogador e as consequências imediatas de suas ações como deixar um personagem morrer em favor de outro e a narrativa prosseguir evidenciando o peso da decisão, e impactos mais duradouros como escolhas que impactam positiva ou negativamente a atitude de outros personagens e afetam seu comportamento em situações futuras.
Ainda assim após essa onda de sucesso em novembro de 2017 a empresa mandou embora 90 de seus funcionários (então 25% do total). E esses foram os sortudos que puderam receber alguma compensação e tiveram tempo de se despedir, porque em uma tarde de setembro de 2018 todo o restante da empresa foi demitido com o aviso de que deveriam deixar o prédio nos próximos 30 minutos. Fontes internas dizem que a diretoria da empresa estava tão obcecada com a idéia que eles teriam uma fórmula mágica em mãos e eles acabaram por não diversificar seu portifólio e investir pesadamente nas mesmas mecânicas de jogo com o mesmo estilo gráfico e a mesma construção de enredo, insistindo em publicar uma série de produtos praticamente idênticos a uma ideia então revolucionária mas após tantos anos de uso e abuso, batida.
Independente da escala usada, é necessário mudar. Mudar para um melhor produto, para pagar menos para entregar valor, ou porque não, para revolucionar sua indústria.
Precisamos especialmente não nos tornarmos também vítimas da inércia ativa: temos como organização uma tendência a seguirmos os mesmos padrões de comportamento que sempre seguimos mesmo em resposta a dramáticas mudanças em nosso ambiente. Somos previsíveis. E tudo o que precisamos combater interna e externamente está a nossa frente e é conhecido e estamos muito bem informados. É necessário mudarmos nossa forma de pensar e agir, do contrário, estaremos nos debatendo mais e mais e no fim não daremos o passo para fora do fosso de areia movediça que estamos, e nos enterraremos mais nele.